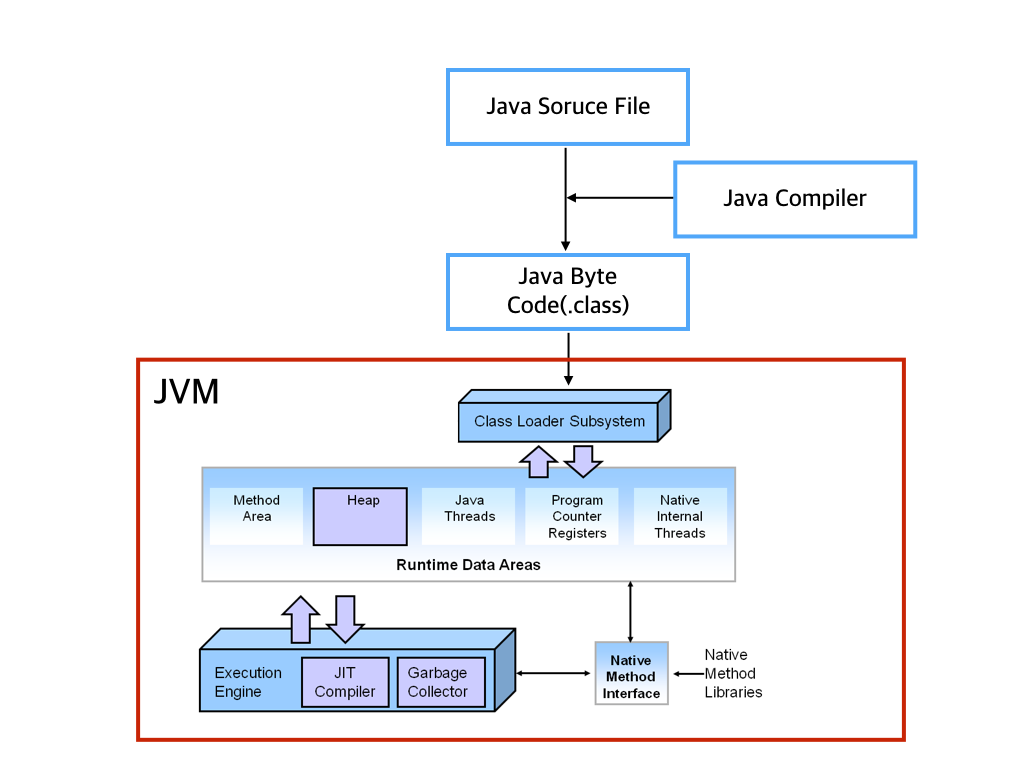
Java Virtual Machine(자바 가상 기계)
OS에 종속받지 않고 CPU 가 Java를 인식, 실행할 수 있게 하는 가상 컴퓨터이다.
Java Byte Code를 OS에 맞게 해석 해주는 역할.
Java compiler는 .java 파일을 .class 라는 Java byte code로 변환.
컴파일
💡 여기서 Java compiler는 JDK를 설치하면 bin 에 존재하는 javac.exe를 말한다. (즉, JDK에 Java compiler가 포함되어 있다는 소리이다.)
Byte Code 는 기계어가 아니기 때문에OS에서 바로 실행되지 않는 데 JVM은 OS가 ByteCode를 이해할 수 있도록 해석
터미널 에서 test.java 파일이 있는 디렉토리에서
명령어 : javac test.java 입력
실행하는 방법
.class 파일이 위치한 곳으로 이동 후 java <.class 파일 이름> 을 입력해 실행시킨다.
명령어 : java test 입력
바이트코드란 무엇인가
자바 바이트 코드(Java bytecode)란 자바 가상 머신이 이해할 수 있는 언어로 변환된 자바 소스 코드를 의미한다.
자바 컴파일러에 의해 변환되는 코드의 명령어 크기가 1바이트라서 자바 바이트 코드라고 불리고 있다.
이러한 자바 바이트 코드의 확장자는 .class이다.
자바 바이트 코드는 자바 가상 머신만 설치되어 있으면, 어떤 운영체제에서라도 실행될 수 있다.
JIT 컴파일러란 무엇이며 어떻게 동작하는가
JIT 컴파일(just-in-time compilation) 또는 동적 번역(dynamic translation)은 프로그램을 실제 실행하는 시점에 기계어로 번역하는 컴파일 기법이다.
JIT는 인터프리터 방식과 정적 방식을 혼합한 방식이다.
인터프리터 방식은 프로그램을 실행할 때마다 컴퓨터가 알아 들을 수 있는 언어로 변환하는 작업을 수행한다.
간편하기는 하지만 성능이 매우 느릴 수 밖에 없다.바이트 코드를 읽어 기계어를 생성 하는데, 코드가 실행되는 과정에서 실시간으로 일어나며 전체코드의 필요한 부분만 변환한다.
하지만 정적 컴파일 방식은 변환 작업을 딱 한번만 한다. 언어로 변환하는 작업을 미리 실행한다.
기본적으로 인터프리터에 의해 수행되지만, 필요한 코드의 정보는 캐시에 담아두었다가(메모리에 담아두었다가 재사용 하게 된다. 정적 컴파일 방식 처럼)
자바 소스코드 -> 자바컴파일러 -> 바이트코드 -> JVM -> 기계어 -> 하드웨어 및 OS의 과정을 거친다.
여기서 JVM -> 기계어로 변환되는 부분을 JIT에서 수행한다.
JIT를 사용하면 반복적으로 수행되는 코드는 매우 빠른 성능을 보이지만, 반대로 처음에 시작할 때에는 변환 단계를 거쳐야 하므로 성능이 느린 단점이 있다.
JVM 구조

- 클래스 로더(Class Loader)
- 실행 엔진(Execution Engine)
- 인터프리터(Interpreter)
- JIT 컴파일러(Just-in-Time)
- 가비지 콜렉터(Garbage collector)
- 런타임 데이터 영역 (Runtime Data Area)
클래스 로더
JVM 내로 클래스 파일(*.class)을 로드하고, 링크를 통해 배치하는 작업을 수행하는 모듈이다.
런 타임시 동적으로 클래스를 로드하고 jar 파일 내 저장된 클래스들을 JVM 위에 탑재한다.
즉, 클래스를 처음으로 참조할 때, 해당 클래스를 로드하고 링크한는 역할을 한다.
실행 엔진
클래스를 실행시키는 역할이다.
클래스 로더가 JVM내의 런타임 데이터 영역에 바이트 코드를 배치시키고, 이것은 실행 엔진에 의해 실행된다.
자바 바이트 코드(*.class)는 기계가 바로 수행할 수 있는 언어보다는 비교적 인간이 보기 편한 형태로 기술된 것이다. 그래서 실행 엔진은 이와 같은 바이트 코드를 실제로 JVM 내부에서 기계가 실행할 수 있는 형태로 변경한다.
인터프리터(interpreter)
자바 컴파일러에 의해 변환된 바이트 코드를 읽고 한 줄씩 기계어로 해석하는 역할을 하는 것이 자바 인터프리터 (interpreter)이다.
원래 JVM에서는 인터프리터 방식만 사용하다가 성능 이슈가 발생해서 JIT 컴파일러를 추가해서 성능을 끌어올렸다. 현 재는 컴파일과 인터프리터 방식을 병행해서 사용한다.
JIT(Just-In-Time)
인터프리터 방식으로 실행하다가 적절한 시점에 바이트 코드 전체를 컴파일하여 기계어로 변경하고, 이후에는 해당 더 이 상 인터프리팅 하지 않고 기계어로 직접 실행하는 방식이다.
💡 컴파일 임계치(Compile Threshold)
- JIT 컴파일러가 메소드가 자주 사용되는 지 체크하는 방식으로 컴파일 임계치를 사용합니다. JIT 컴파일러가 내부적으 로 메서드가 호출될 때마다 호출 횟수를 카운팅하고 그 횟수가 특정 수치를 초과할 때 캐싱해서 이후에는 JIT 컴파일이 트리거된다.
프로그램이 실행 중인 런타임 중에 여러번 호출되는 메소드들을 미리 만들어 둔 해석본을 이용해서 컴파일하는 역할을 하는 것이 JIT 컴파일러이다.
가비지 컬렉터(garbage collector)
가비지 컬렉터(garbage collector)는 메모리 관리를 자동으로 해줘서 개발자가 비즈니스 로직에 더 집중할 수 있게 도와준 다.
Runtime Data Area

Runtime Data Area는 JVM이 프로그램을 수행하기 위해 OS로부터 할당받는 메모리 영역이다.
WAS의 성능에 문제가 발생했을 때, 대부분 이 영역들이 원인이 된다.
Runtime Data Area는 5가지로 구분된다.
| PC Register | JVM stack | Native Method stack | Heap | Method Area |
좌측 3개의 영역은 Thread별로 생성되고, 우측 2개의 영역은 모든 Thread가 공유한다.
PC Register
Thread가 시작될 때 생성되며 생성될 때마다 생성되는 공간으로, 스레드마다 하나씩 존재한다.
Thread가 어떤 부분을 어떤 명령으로 실행해야할 지에 대한 기록을 하는 부분으로 현재 수행 중인 JVM 명령의 주소를 갖는다.
💡 스레드(thread)란?
스레드(thread)란 프로세스(process) 내에서 실제로 작업을 수행하는 주체를 의미
모든 프로세스에는 한 개 이상의 스레드가 존재하여 작업을 수행한다.
JVM 스택 영역
Thread의 Method가 호출될 때 수행 정보(메소드 호출 주소, 매개 변수, 지역 변수,
연산 스택)가 Frame 이라는 단위로 JVM stack에 저장된다.
그리고 Method 호출이 종료될 때 stack에서 제거된다.
Native method stack
자바 프로그램이 컴파일되어 생성되는 바이트 코드가 아닌 실제 실행할 수 있는 기계어로 작성된 프로그램을 실행시키는 영역.
JAVA가 아닌 다른 언어로 작성된 코드를 위한 공간.
Java Native Interface를 통해 바이트 코드로 전환하여 저장하게 된다.
일반 프로그램처럼 커널이 스택을 잡아 독자적으로 프로그램을 실행시키는 영역
Method Area (= Class Area = Static area)
Class Loader가 적재한 클래스(또는 인터페이스)에 대한 메타데이터 정보가 저장된다.
이 영역에 등록된 class만이 Heap에 생성될 수 있다.
사실 Method Area는 논리적으로 Heap에 포함된다.
더 구제적으로는 Heap의 PermGen이라는 영역에 속한 영역인데,
Java 8 이후로는 Metaspace라는 OS가 관리하는 영역으로 옮겨지게 된다.
Runtime Constant Pool
스태틱 영역에 존재하는 별도의 관리영역.
상수 자료형을 저장하여 참조하고 중복을 막는 역할을 수행한다.
| Type Information | - Type(class or interface)의 전체 이름 - Type의 직계 하위 클래스 전체 이름 - Type의 class/interface 여부 - Type의 modifier (public / abstract / final) - 연관된 interface 이름 리스트 |
| Field Information |
- Field Type - Field Modifier (public / private / protected / static / final / volatile / transient) |
| Method Information | - Constructor를 포함한 모든 Method의 메타 데이터를 저장 |
| Runtime Constant Pool | - Type, Field, Method로의 모든 레퍼런스를 저장 - JVM은 이 영역을 통해 실제 메모리 상의 주소를 찾아 참조 |
| Class Variable | - static 키워드로 선언된 변수를 저장 - 기본형이 아닌 static 변수는 레퍼런스 변수만 저장되고 실제 인스턴스는 Heap에 저장됨 - 클래스를 사용하기 이전에 이 변수들은 미리 메모리를 할당받음 |
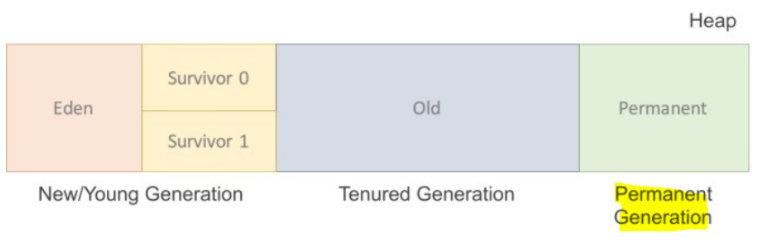
Heap 영역
객체를 저장하는 가상메모리 공간. new 연산자로 생성되는 객체와 배열을 저장한다.
Class Area(Static Area)에 올라온 클래스들만 객체로 생성할 수 있다.(당연함)
힙은 세 부분으로 나뉘어 진다.
Permanent Generation
직역하면 영구적인 세대이다.
생성된 객체들의 정보의 주소값이 저장된 공간이다. 클래스 로더에 의해 load되는 Class, Method 등에 대한 Meta 정보가 저장되는 영역이고 JVM에 의해 사용된다.
Reflection을 사용하여 동적으로 클래스가 로딩되는 경우에 사용된다.
💡 Reflection이란?
객체를 통해 클래스의 정보를 분석해 내는 프로그래밍 기법
구체적인 클래스 타입을 알지 못해도, 컴파일된 바이트 코드를 통해
역으로 클래스의 정보를 알아내어 사용할 수 있다는 뜻이다.
New/Young 영역
이곳의 인스턴스들은 추후 가비지 콜렉터에 의해 사라진다.
생명 주기가 짧은 “젊은 객체”를 GC 대상으로 하는 영역이다.
여기서 일어나는 가비지 콜렉트를 Minor GC 라고 한다.
Eden: 객체들이 최초로 생성되는 공간
Survivor 0, 1: Eden에서 참조되는 객체들이 저장되는 공간
Old 영역
이곳의 인스턴스들은 추후 가비지 콜렉터에 의해 사라진다.
생명 주기가 긴 “오래된 객체”를 GC 대상으로 하는 영역이다.
여기서 일어나는 가비지 콜렉트를 Major GC 라고 한다. Minor GC에 비해 속도가 느리다.
New/Young Area에서 일정시간 참조되고 있는, 살아남은 객체들이 저장되는 공간이다.
JRE와 JDK 차이점
JRE(Java Runtime Environment)란?
JRE란 번역하면 자바 실행환경으로 자바 프로그램을 실행하는데 필요한 것이다.
즉, 자바 프로그램을 실행시키는데는 문제가 없지만 자바 프로그램을 코딩할 때 jdk가 아니라 jre를 사용하면 문제점이 생길 수 있다.
예를 들어 컴파일이 정상적으로 되지 않을 수도 있다.
JDK(Java Development Kit)란?
번역하면 자바 개발 키트이다. 간단하게 설명하면 자바를 개발하는데 필요한 기능들이 들어간 것이다.
여기에는 물론 자바를 실행하는데 필요한 jre도 포함되어 있어서 jdk를 다운로드 받으면 jre 또한 포함되어 있다.
자바 프로그램 개발을 위해서는 바로 이 jdk를 다운로드 받아 자바 기능을 사용하고 컴파일 해야하는 것이다.
즉, 정리해보면 자바 프로그램을 실행시키는데 필요한 것이 바로 jre이고 자바 프로그램을 개발하는데 필요한 것이 jdk이다.
jdk를 다운로드 받으면 jre도 포함되어 있어 개발한 자바 프로그램을 실행시키는 것까지 가능하다.
'JAVA > 참고 개인공부' 카테고리의 다른 글
| 핵클 협력사 세션. (0) | 2022.10.04 |
|---|---|
| 인터페이스 (0) | 2022.09.30 |